Anthropic 宣布将 Claude Opus 升级到新版本:Claude Opus 4.8。这一版本基于 Opus 4.7 进一步提升,在多项基准测试中表现更好,也成为一个更有效的协作伙伴。该模型现已开放使用,常规价格保持不变。目前https://api.aekor.com/ 已经接入了Claude Opus 4.8,欢迎大家体验
Claude Opus 4.8 与多项新功能同步推出。claude.ai 用户现在可以控制 Claude 在任务中投入的努力程度;Claude Code 新增 dynamic workflows 功能,可以处理更大规模的问题;同时,Claude Opus 4.8 的 fast mode 可让模型以约 2.5 倍速度工作,并且价格比此前模型的 fast mode 降低到三分之一。
Claude Opus 4.8 的能力
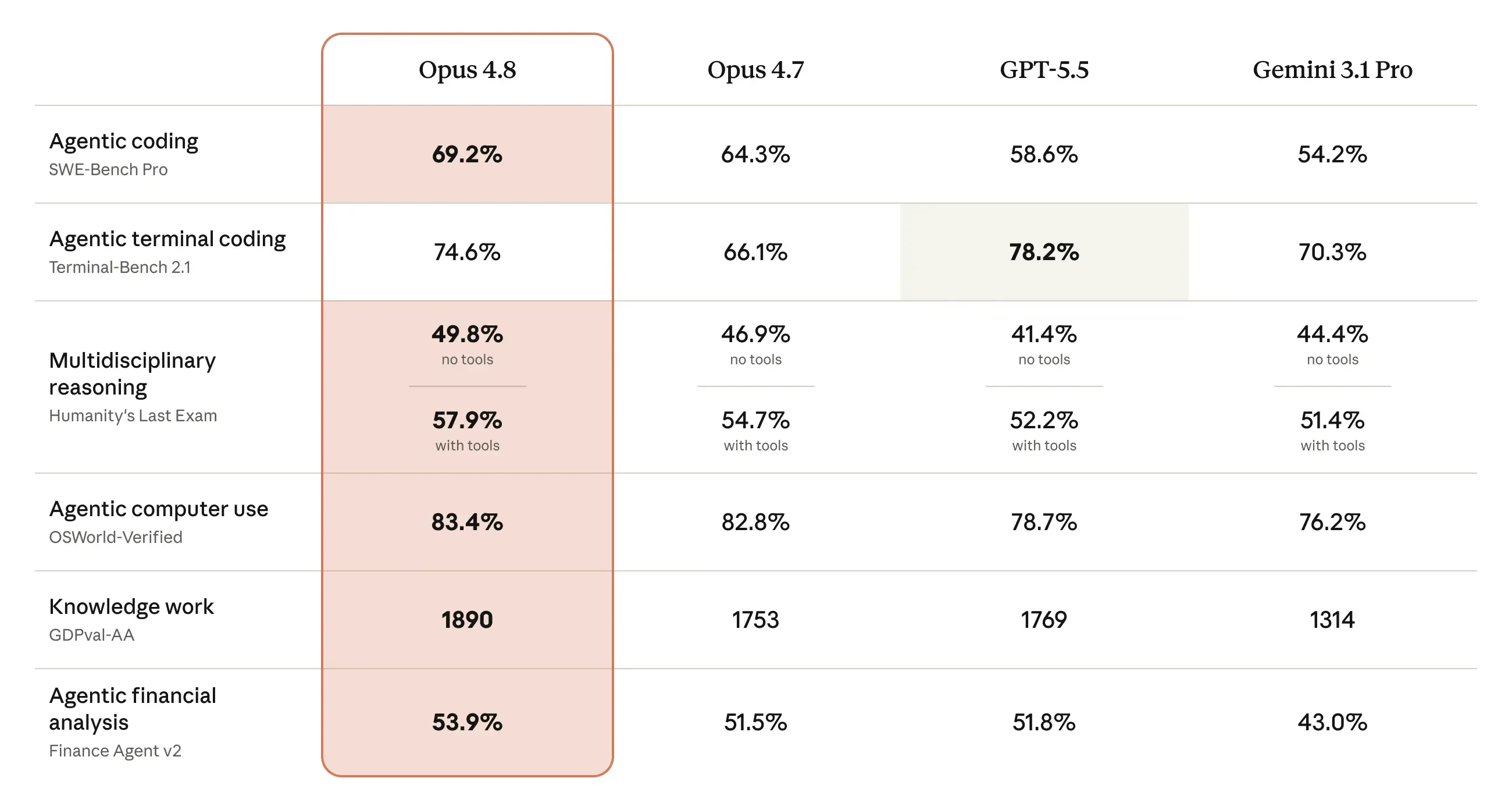
下表用于说明 Claude Opus 4.8 与上一代模型以及其他模型在代码、智能体能力、推理能力和实际知识工作任务中的表现差异。更多能力评估细节可在 Claude Opus 4.8 System Card 中查看。
与 Claude Opus 4.8 协作
早期测试者认为,Claude Opus 4.8 在执行智能体任务时更加可靠,判断更敏锐。许多测试者反馈,它在 Claude Code 中会提出更合适的问题,能够发现自己的错误,在计划不合理时提出质疑,并在复杂、多服务探索中逐步建立信心后再进行重大改动。
测试者还提到,Claude Opus 4.8 在一些智能体基准测试中展现出较强的端到端完成能力;在翻译、深度研究、幻灯片制作、分析、法律工作、浏览器智能体、工程任务、金融文档处理等场景中,都表现出更高的稳定性、效率和实用性。
其中一个突出改进是诚实性。Anthropic 表示,他们会训练所有模型保持诚实,例如避免做出无法支持的断言。AI 模型普遍存在的问题是,有时会过早下结论,即使证据不足,也会自信地声称已经取得进展。早期测试显示,Claude Opus 4.8 更倾向于指出自己工作中的不确定性,也更少做出缺乏依据的结论。
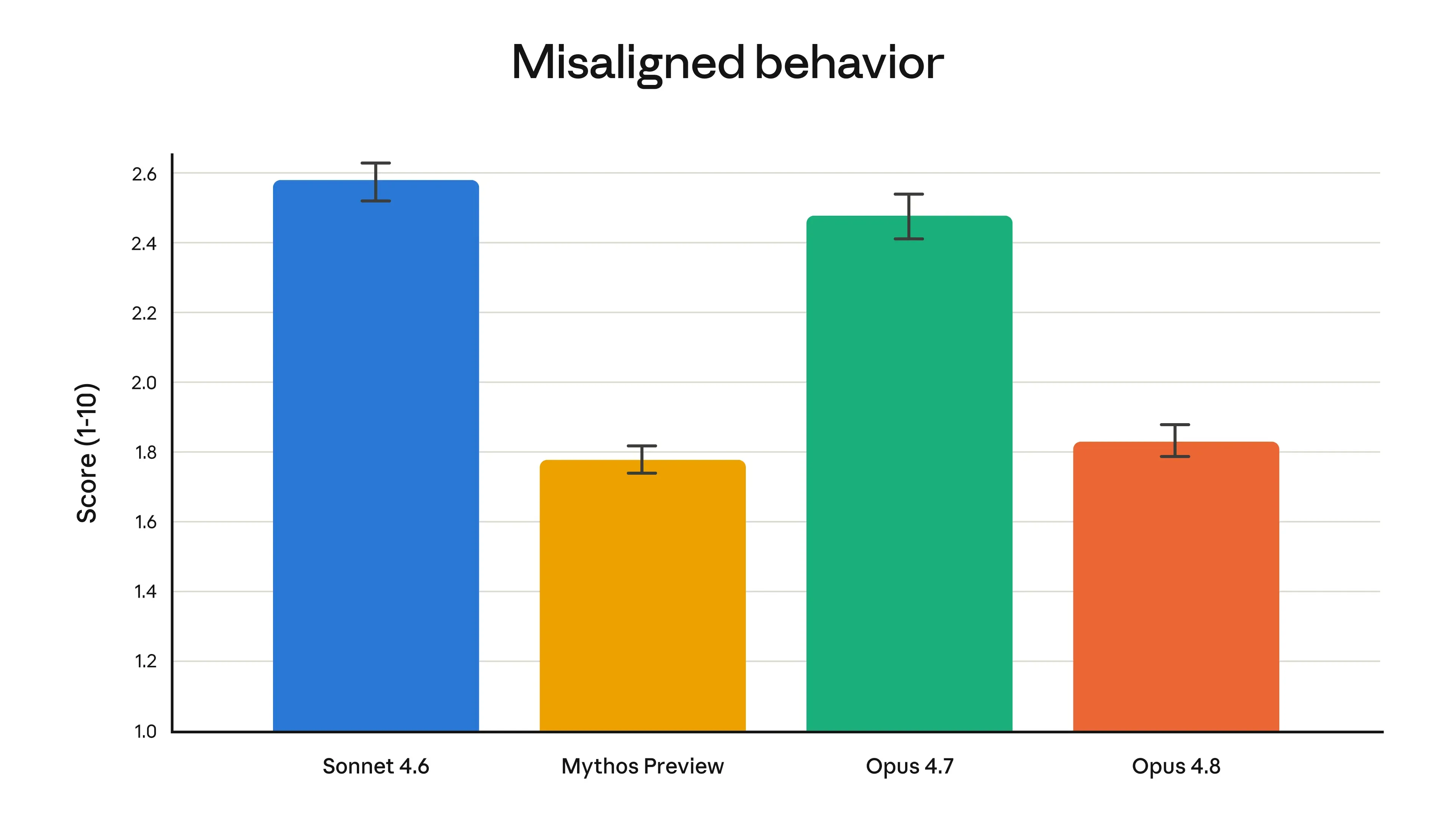
评估结果显示,相较上一代模型,Claude Opus 4.8 在自己编写的代码存在缺陷时,更不容易忽略这些问题。Anthropic 还在发布前对该模型进行了详细的对齐评估。其 Alignment 团队认为,Claude Opus 4.8 在支持用户自主性、维护用户最佳利益等亲社会特质指标上达到了新的高度。评估还显示,该模型在欺骗、配合滥用等不对齐行为方面的比例明显低于 Opus 4.7,并与 Claude Mythos Preview 这类对齐表现较好的模型接近。
今天同步推出的更新
除了 Claude Opus 4.8,Anthropic 还发布了以下更新:
dynamic workflows:这是 Claude Code 中的新功能,目前以 research preview 形式提供。它允许 Claude 承担更大的任务,能够先规划工作,再在单个会话中运行数百个并行子智能体,并在向用户汇报之前验证输出结果。借助 Claude Opus 4.8,这些智能体可以运行更长时间。例如,Claude Code 搭配 Opus 4.8 后,可以完成涉及数十万行代码的大规模代码库迁移,从启动任务一直推进到合并,并以现有测试套件作为检验标准。该功能面向 Claude Code 的 Enterprise、Team 和 Max 计划开放。
effort control:claude.ai 和 Cowork 中新增了努力程度控制。用户可以在模型选择器旁边选择 Claude 对回复投入多少努力。更高的努力设置会让 Claude 更频繁、更深入地思考,从而给出更好的回答;更低的努力设置则可以让 Claude 响应更快,并更慢地消耗用户的速率限制。该功能面向所有计划开放。
Claude API 更新:Messages API 现在支持在 messages 数组中加入 system entries。开发者可以在任务中途更新 Claude 的指令,而不会破坏 prompt cache,也不需要通过用户回合传递更新。这可以用于在智能体运行过程中更新权限、token 预算或环境上下文。
关于 effort 的说明
Claude Opus 4.8 默认使用 high effort。Anthropic 认为,这是质量与用户体验之间最好的整体平衡。在代码任务中,这一努力等级消耗的 token 数量与 Opus 4.7 默认设置接近,但性能更好。
用户也可以选择 extra,在 Claude Code 中对应 xhigh,或者选择 max。模型会消耗更多 token,以获得更好的结果。Anthropic 建议在困难任务和长时间运行的异步工作流中使用 extra。
为了适应更高 effort 等级带来的 token 使用量增加,Anthropic 已提高 Claude Code 的速率限制。用户可以根据具体项目选择合适的设置。
接下来
Anthropic 表示,用户会发现 Claude Opus 4.8 相比上一代模型有适度但明确的提升。与此同时,他们仍在继续开发和发布能够以更低成本提供许多 Opus 能力的新模型。
此外,Anthropic 计划发布一类智能水平高于 Opus 的新模型。作为 Project Glasswing 的一部分,少数组织目前正在使用 Claude Mythos Preview 进行网络安全工作。这一级别能力的模型在正式广泛发布之前,需要更强的网络安全防护措施。Anthropic 表示,相关防护措施正在快速推进,并预计未来几周可将 Mythos 级别模型带给所有客户。
可用性
Claude Opus 4.8 现已全面可用。常规使用价格与 Opus 4.7 保持一致:每百万输入 token 5 美元,每百万输出 token 25 美元。fast mode 的价格为每百万输入 token 10 美元,每百万输出 token 50 美元。开发者可以通过 Claude API 使用 claude-opus-4-8。
脚注信息
Terminal-Bench 2.1:Anthropic 使用 Terminus-2 public harness 报告所有模型的分数。GPT-5.5 使用 Codex CLI harness 的报告分数为 83.4%。
OSWorld-Verified:Anthropic 对 OSWorld-Verified 评估方式进行了调整,以更准确反映模型在真实世界中的表现,并将 Opus 4.7 分数更新为 82.3%。更多信息可查看 System Card。
Finance Agent v2:Gemini 3.5 Flash 在 Finance Agent v2 上得分为 57.9%,相比 Gemini 3.1 Pro 有显著提升。

文章评论
All the best